miniMIPS Superscalar
The microarchitecture is the same as the 2004 minimips but with the addition of a new multiplication instruction whose operands must have at most the first 16 significant bits and the result of the multiplication is written directly in the general purpose registers in the same way as the R type instructions. The architecture is obviously not the same as its base processor. I'll name it MIPS1_M maybe ... It's a new architecture, there is no GNU compiler with configuration options for the superscalar minimips architecture. I make the assembly programs by hand and generate the binary file in GASM.
In the figure below, notice that the compiler arranged the instructions with nops after the load word instructions; this caused the two load instructions that are inside the loop to be executed only by one of the pipelines at each iteration. Consequently, the execution time of each loop is longer than if the load instructions were divided one for each pipeline, the stop time for accessing the memory is serialized, that is, it is multiplied by 2. It is prohibitive to run this stretch of code using the superscalar minimips .
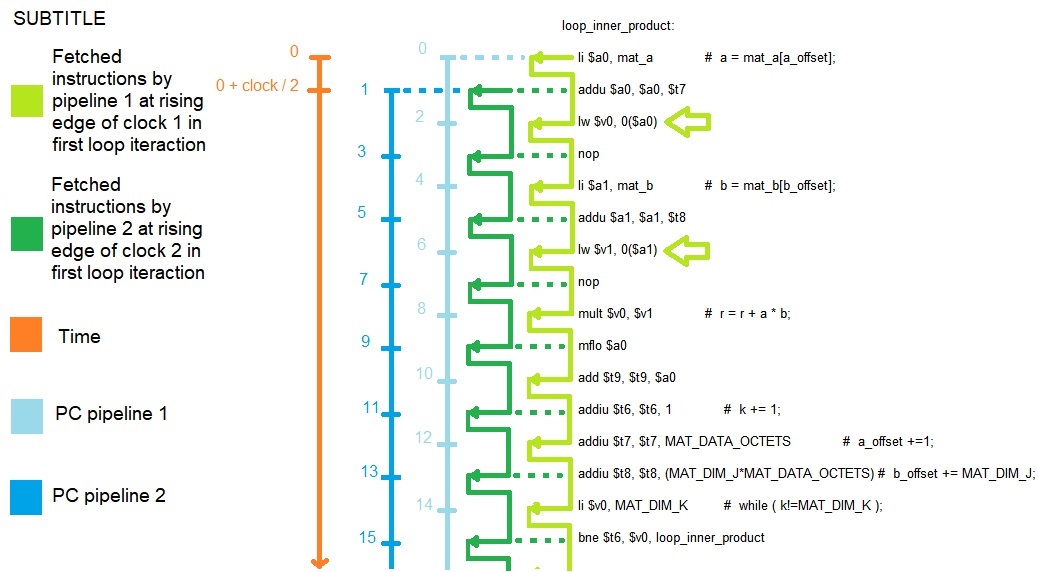 Another important note in the code snippet above the li and addu instructions, in the first two lines of code; they have the same destination address and will be executed one in each pipeline within the same cycle, which can cause the result not to be written in the register bank. Then it will be better if they are searched for one of the pipelines just by inserting a nop between them so that not cause an unsolved data hazard. It is not interesting to use these instructions inside loops. Especially if the two have the same destination address and are at adjacent addresses. The combination of the li and lui instructions with the same destination address also produces the same hazard in this dispositon.
Another important note in the code snippet above the li and addu instructions, in the first two lines of code; they have the same destination address and will be executed one in each pipeline within the same cycle, which can cause the result not to be written in the register bank. Then it will be better if they are searched for one of the pipelines just by inserting a nop between them so that not cause an unsolved data hazard. It is not interesting to use these instructions inside loops. Especially if the two have the same destination address and are at adjacent addresses. The combination of the li and lui instructions with the same destination address also produces the same hazard in this dispositon.
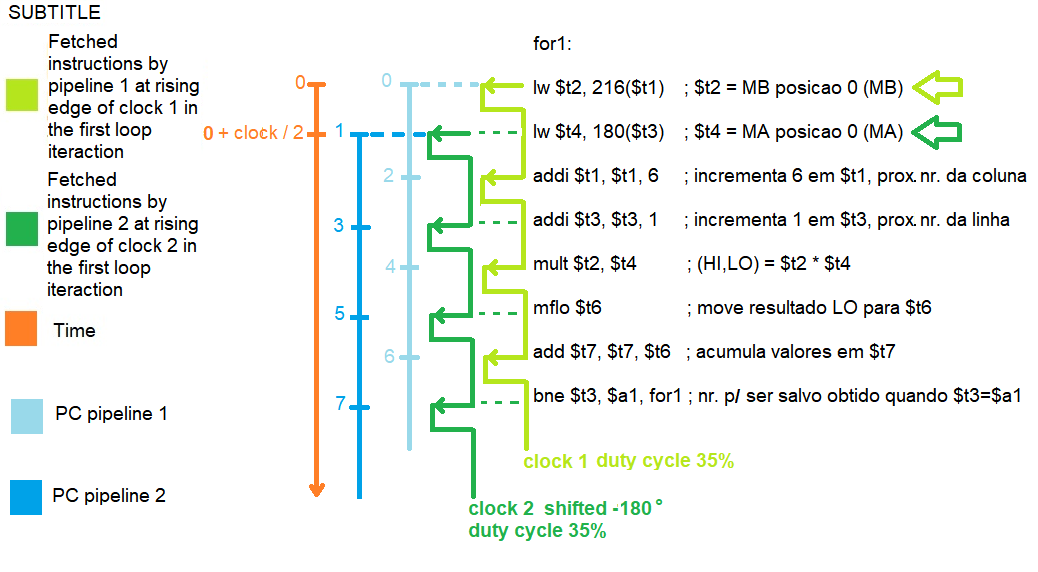
The code snippet in the following figure is an example that does the same as the previous code snippet (searches for two operands in memory, increments two pointers, multiplies the operands and accumulates the results) but will make the stop time for the memory access to be divided by 2.