
SPI Master/Slave Interface
Project maintainers
Details
Created: May 16, 2011
Updated: Dec 20, 2017
SVN Updated: Sep 19, 2011
SVN: Browse
Latest version: download (might take a bit to start...)
Statistics: View
Bugs: 18 reported / 8 solved
Other project properties
Language:VHDL
Development status:Stable
Additional info:ASIC proven, Design done, FPGA proven, Specification done
WishBone compliant: No
WishBone version: n/a
License: LGPL
Development Status
Please if you are using this core, report if the marked bugs (CPHA='1', bit alignment) are solved for your toolchain.
You can send me e-mail to jdoin@opencores.org
I have confirmation from people using Xilinx ISE 13.1, 12.4 and 12.1 with WebPack, Altium + ISE 12.3, Synopsys and Altera tools.
I would like to know if the VHDL style used in this core works for your toolchain, and if not, what seems to be the problem.
My goal is to find a description style that is as friendly as possible to synthesis tools.
In the example, the slave is used with wren_i permanently tied to HIGH. The parallel input data is sampled from di_i at start of transmission, until the first SPI SCK edge. For continuous transfers, the data at di_i is sampled again every falling edge on state 1.
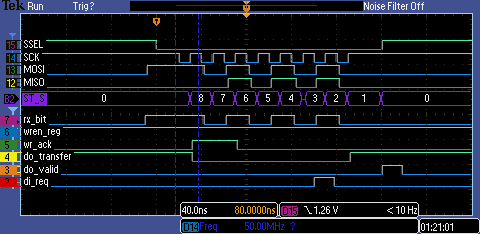
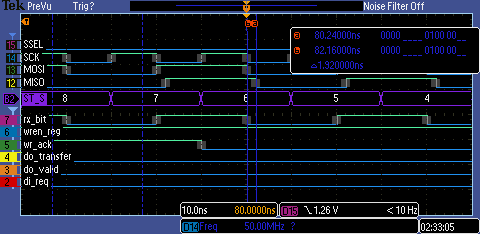
The scope screens below show 2 examples of continuous transfers: for CPOL=1, CPHA=0 and CPOL=0, CPHA=0 spi modes. The words are loaded when 'di_req' line goes to '1'. Data is presented to the port di_i and wren_i is pulsed to write the data word.
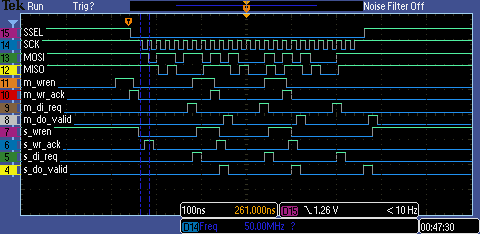
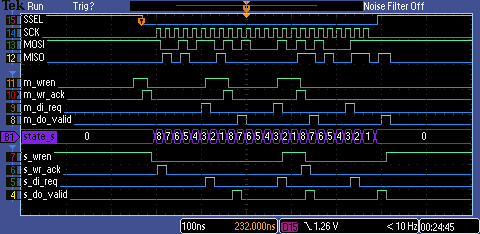
Related Links
The following OpenCores projects are related to this:
- Multiple Switch Debouncer in VHDL: http://opencores.org/project,debouncer_vhdl , used in the FPGA verification project.
To get the latest version: http://opencores.org/download,spi_master_slave
To see the scope screenshots: http://opencores.org/project,spi_master_slave,downloads
See all scope photos in the 'trunk/syn' folder at the SVN: http://opencores.org/websvn,filedetails?repname=spi_master_slave&path=%2Fspi_master_slave%2Ftrunk%2Fsyn%2Fspi_master_scope_photos.zip
If you have issues you like to be addressed, place a request in the bugtracker: http://opencores.org/project,spi_master_slave,bugtracker , or send me an e-mail at jdoin@opencores.org
Description
This project started from the need to have robust yet simple SPI interface cores written in VHDL to use in generic FPGA-to-device interfacing.
The resulting cores generate small and efficient circuits, that operate from very slow SPI clocks up to over 50MHz SPI clocks.
The project contains 2 independent cores: SPI_MASTER and SPI_SLAVE.
Both cores are written in VHDL, with fully pipelined RTL architecture and separate clock domains for the SPI bus clock and parallel I/O interface.
The design is originally targeted to a Spartan-6 device, but is written in fully synthesizable, technology-independent VHDL.
The circuits preserve FPGA clock resources by directly using the system high speed clock for all flops, with clock enables (CE) to clock registers.
The master and slave cores were verified in hardware using the Digilent Atlys board (Spartan-6 @100MHz) with spi clocks from 500kHz to 50MHz SPI clock, with perfect phasing and very robust operation.
If you find these cores useful, please let me know: jdoin@opencores.org
If you find the LGPL license to be unfit for your purposes, please let me know and we can change the license for another open-source hardware license that can be integrated in your application.
Features
- VHDL core, fully synchronous, designed with classic RTL pipelined architecture, with a single high-speed global clock
- Very small and efficient SPI interface
- Parameterizable at instantiation by generics: (N, CPOL, CPHA, PREFETCH, SPI_2X_CLK_DIV)
-> SPI modes (CPOL, CPHA): supports modes 0,1,2,3
-> Word width (N): from 8 bits to synthesis limit (accepts any word length)
-> Lookahead input data request (PREFETCH): pipelined data request for back-to-back data transmission
-> SPI 2x clock divider value from the high-speed system clock
- Very economic: no FIFO, just a registered parallel output buffer for received data
- Parallel read/write similar to synchronous RAM ports
- Independent clock domains for the serial bus and parallel read/write ports with async domain transfer pipelines
- Can be used to control generic SPI devices (master), or as interface to MCUs (slave)
- Vendor-independent, fully LUT/FF design, uses no Xilinx-specific structures, IOBs or shift registers
- Synthesizes to +210MHz in a Spartan-6 lowest grade, using only CLB logic
- Verified in silicon, with a 100MHz clock, using SPI frequencies from 500kHz up to 50MHz in a Spartan-6 XC6SLX45-2
- Very small: 41 slices for 2 ports (a master interface + a slave interface) with 32bits of word length